Innhold i denne artikkelen
LLM er forkortelsen du møter overalt når samtalen handler om KI, men de færreste får en skikkelig forklaring på hva det faktisk er. De fleste tror den googler — det er ikke helt feil, men det er heller ikke helt rett, og misforståelsen har praktiske konsekvenser for hvordan du forholder deg til KI-synlighet.
Hva er en LLM?
LLM står for Large Language Model, eller stor språkmodell på norsk. Det er teknologien som ligger bak de KI-verktøyene du hører om overalt: ChatGPT fra OpenAI, Gemini fra Google, Claude fra Anthropic og en rekke andre.
En LLM er i bunn og grunn en veldig avansert gjetningsmaskin. Den har lest enorme mengder tekst fra internett, bøker og artikler, og har lært seg ett grunnleggende mønster: gitt en sekvens av ord, hva er det mest sannsynlige neste ordet? Ikke fordi den forstår betydning slik vi gjør, men fordi den har sett nok tekst til å gjenkjenne mønstre veldig presist.
Det som gjør moderne LLM-er spesielle er ikke at de er smartere enn den enkle beskrivelsen over, men at de er trent på så mye data og med så mange parametre at mønstergjenkjenningen blir ekstremt sofistikert. De kan resonnere, oppsummere, oversette og skrive kode — ikke fordi de tenker, men fordi de har sett nok eksempler på at det gjøres.
Det er også derfor de noen ganger tar feil med stor selvtillit. Når modellen ikke har nok mønster å gå på, gjetter den fortsatt, og gjetningen kan høres like overbevisende ut som når den har rett.
Så googler en LLM eller ikke?
Her er misforståelsen som går igjen, og den er verdt å rydde opp i skikkelig.
Grunnmodellen er en LLM uten internettilgang. Den opererer utelukkende fra det den er trent på: enorme mengder tekst prosessert og lagret som matematiske representasjoner. Ingen live-søk, ingen nettleser, ingen sanntidsdata. Den vet det den har lært, og gjetter derfra.
Modellen med verktøy er en annen sak. ChatGPT med browsing aktivert, Perplexity og lignende kan hente live-informasjon fra nettet. Men det er et lag oppå LLM-en, ikke en iboende egenskap. Når det skjer, er det ikke modellen som googler — det er et verktøy modellen bruker, og resultatet mates tilbake til modellen som tekst.
Semrush-analyse av over én milliard linjer clickstream-data viser at ChatGPT aktiverer søkefunksjonen på 34,5 prosent av spørsmål per februar 2026, ned fra 46 prosent i slutten av 2024. Det betyr at for flertallet av spørsmål er det det du spurte om, og kvaliteten på det som er tilgjengelig om emnet, som avgjør om modellen kjenner svaret.
Slik finner en LLM informasjon: vektorer og semantisk søk
Her er den delen de fleste aldri får forklart ordentlig, og den gjør plutselig mye annet mer forståelig.
Ord lagres ikke som tekst. De lagres som koordinater.
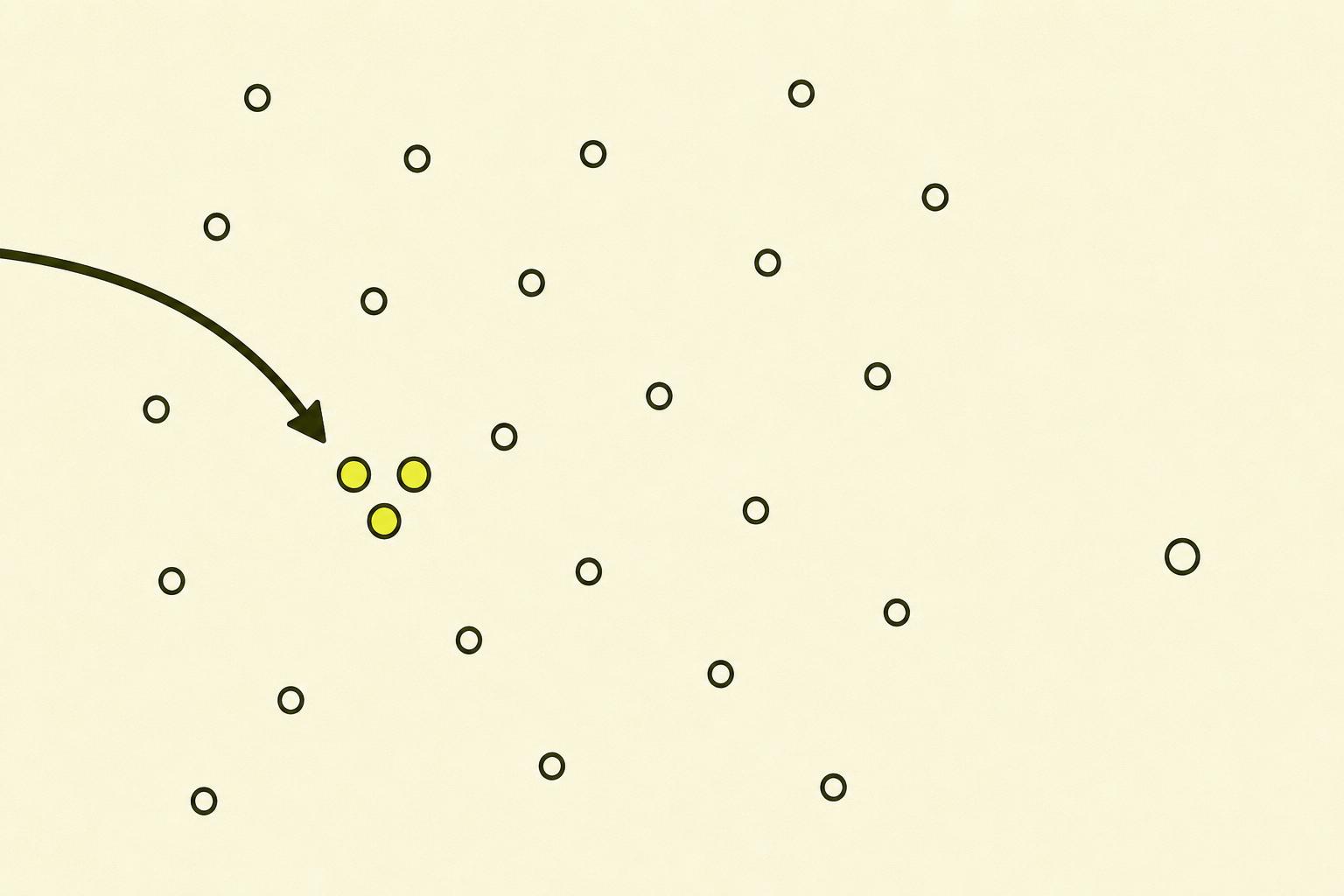
Tenk deg et gigantisk rom med millioner av flytende punkter. Hvert ord, hvert konsept, har sin egen plassering i dette rommet, og plasseringen er ikke tilfeldig. Den bestemmes av hvilken sammenheng ordet typisk dukker opp i.
«Hund» og «valp» flyter rett ved siden av hverandre. «Hund» og «asfalt» er i forskjellige hjørner. «Rente» plasseres et sted nær «bank» når det handler om finans, og et annet sted nær «hage» når det handler om planter. Samme ord, ulik plassering avhengig av konteksten rundt.

Ifølge OpenAIs tekniske dokumentasjon har embedding-modeller typisk mellom 1 536 og 3 072 dimensjoner — langt utover hva et menneske kan forestille seg. Men prinsippet er det samme: nærhet i rommet betyr likhet i betydning.
Søket er egentlig en avstandsberegning
Når du stiller et spørsmål til en LLM, gjøres spørsmålet ditt om til en vektor — et sett med koordinater i det samme rommet. Modellen finner deretter informasjonen med koordinater som ligger nærmest ditt spørsmåls koordinater. Det er ikke søk etter bokstaver, det er søk etter betydning.
Det er derfor LLM-er forstår synonymer og kontekst på en måte tradisjonelle søkemotorer ikke klarte. Et søk på «liten valp» finner «lite hundedyr» fordi koordinatene er nesten identiske. Et søk på «kostnadsreduksjon» finner «budsjettbesparelser» av samme grunn.
| Søketype | Mekanisme | Resultat for «small puppy» |
|---|---|---|
| Nøkkelordsøk | Finner eksakt tekst | Finner «small» + «puppy». Mister «tiny dog» |
| Vektorsøk | Finner nærmeste koordinater | Finner «tiny dog», «little hound» og «puppy» |
Når en LLM faktisk henter informasjon: RAG
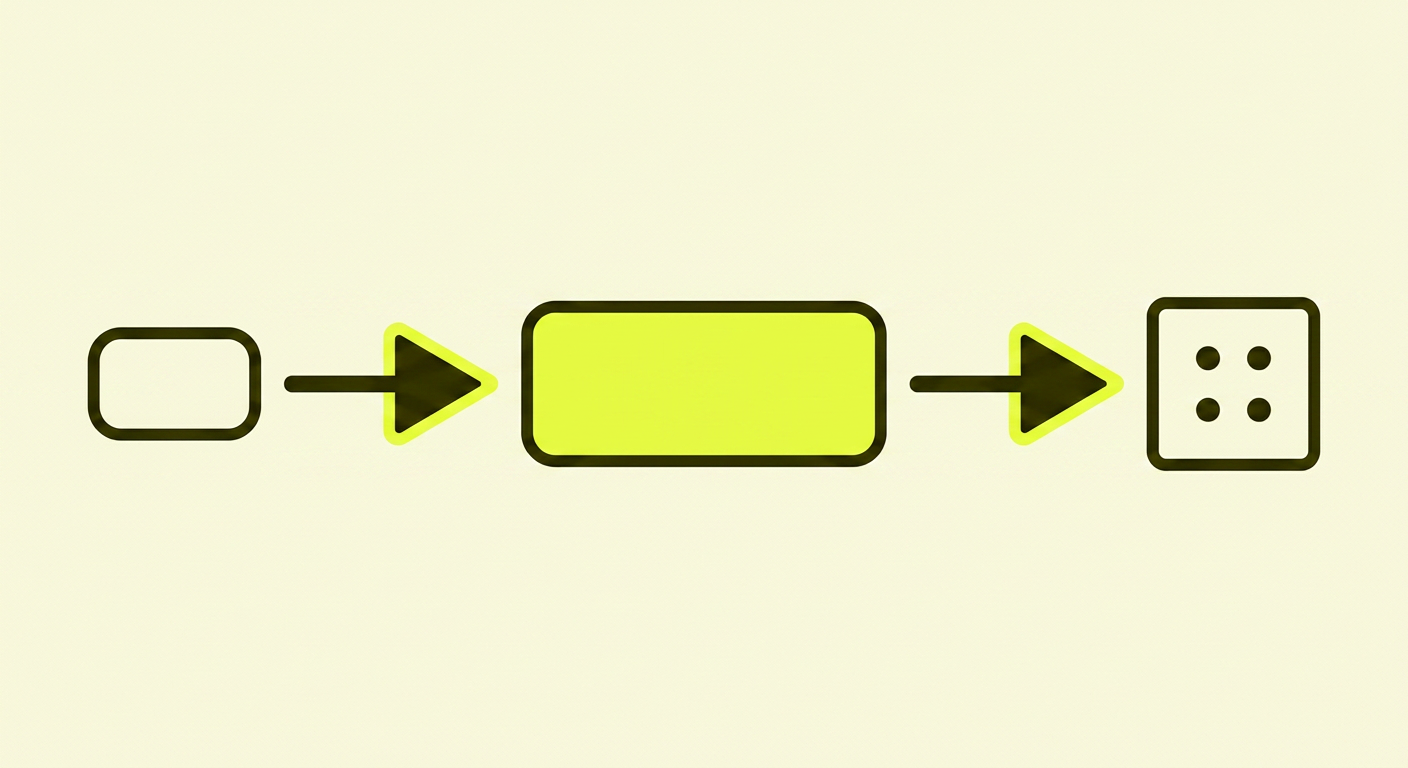
Når ChatGPT med browsing aktivert, Perplexity eller en bedriftsintern KI-løsning henter ekstern informasjon, skjer det gjennom en prosess kalt RAG — Retrieval-Augmented Generation.
Forenklet ser det slik ut:
- Spørsmålet ditt gjøres om til en vektor
- Systemet søker i en vektordatabase etter de nærmeste koordinatene — de mest relevante tekstbitene
- De mest relevante bitene hentes ut og mates inn til LLM-en som kontekst
- LLM-en bruker denne konteksten til å formulere et svar
Når ChatGPT søker på nett, er det i praksis RAG med live-web som datakilde i stedet for en forhåndsprosessert database. LLM-en googler ikke. Den får servert relevante tekstbiter basert på vektornærhet, og bruker dem til å svare.
Bing, Google — eller begge?
En studie fra Backlinko i august 2025 utfordret antagelsen om at ChatGPT bare bruker Bing: de publiserte en side som bare var indeksert i Google, og ChatGPT ga et korrekt svar om den til tross for at Bing aldri hadde sett siden. ChatGPT ser dermed ut til å hente fra flere søkekilder enn Bing alene, avhengig av modell og kontekst.
Ifølge Search Engine Land bruker ChatGPT-agenter likevel Bing Search API i 92 prosent av live-søk. Det betyr at Bing-indeksering fortsatt er viktig — men ikke lenger det eneste som teller.
Vil du grave dypere i den praktiske siden av dette, har jeg skrevet en egen artikkel om hva GEO er og hvordan du blir synlig i KI-søk — og en kort gjennomgang av llms.txt og om du faktisk trenger det.
Hva betyr alt dette for deg som bedriftseier?
Grunnmodellen henter fra det den er trent på
For LLM-er uten live-søk avgjøres synligheten av hva som var tilgjengelig og godt nok da modellen ble trent. Autoritativt, konsistent og strukturert innhold om et emne har høyere sjanse for å ha fått høy vektornærhet til relevante spørsmål, og dermed høyere sjanse for å bli sitert.
RAG-systemer henter fra det som er indeksert og tilgjengelig
For live-søk-systemer som ChatGPT med browsing og Perplexity er spørsmålet: er nettstedet ditt indeksert der systemet søker? Basert på tilgjengelig data betyr det både Bing og Google, men med Bing som den dominerende kilden.
Semantisk autoritet i et emne teller mer enn enkeltord
Fordi LLM-er opererer med vektornærhet, er det ikke ett nøkkelord som avgjør om du er en relevant kilde. Det er den samlede semantiske tettheten av innholdet ditt rundt et emne. Ti grundige artikler om ett fagfelt gir høyere semantisk autoritet enn hundre overfladiske artikler om mange temaer.
Strukturerte definisjoner er lettere å vektorisere og hente
En tydelig, selvstendig definisjon tidlig i teksten gir modellen et presist koordinatpunkt å hente fra. Det er grunnen til at klare H2-er, FAQ-seksjoner og direkte svar på konkrete spørsmål gir bedre GEO-synlighet. Ikke fordi det er et triks, men fordi det gjenspeiler hvordan LLM-er faktisk opererer.
Oppsummert: Min mening
Du trenger ikke å forstå vektorer og RAG for å lage godt innhold. Men det hjelper å forstå at «LLM-en googler» er en forenkling som skjuler noe viktig.
En LLM er ikke en søkemotor. Den er en meningsfinner. Den henter det som ligger nærmest spørsmålet ditt i et enormt matematisk rom, og formulerer et svar basert på det. Om den henter det fra treningsdata eller live-web avhenger av hvilken modus den er i, ikke av hva du tror den gjør.
Konsekvensen er den samme uansett: tydelig, strukturert, autoritativt innhold om et emne gir deg bedre posisjon i det rommet der LLM-en leter. Det er ikke mer mystisk enn det.
Her kan du lese mer
- ChatGPT traffic analysis — 17 months of clickstream data — datagrunnlaget for 34,5 prosent-tallene
- ChatGPT Is Using Google Search — We Tested It — dokumentasjon på at ChatGPT ikke utelukkende bruker Bing
- OpenAI: New embedding models and API updates — teknisk dokumentasjon om vektordimensjoner
- Bing Webmaster Tools — verifiser at nettstedet er indeksert for ChatGPT-synlighet
Jeg holder meg oppdatert på disse kildene daglig, slik at du slipper å gjøre det.